Create VPC Endpoint for AWS lambda to access IoT Timestream DB
28. 7. 2023

Time series data is a sequence of data points recorded over a time interval. This type of data is used for measuring events that change over time, such as stock prices, temperature measurements, or CPU utilization , generally IoT data. With time series data, each data point consists of a timestamp, one or more attributes, and the event that changes over time. You can use this data to derive insights into the performance and health of an application, detect anomalies, and identify optimization opportunities. For example, DevOps engineers might want to view data that measures changes in infrastructure performance metrics. Manufacturers might want to track internet of things (IoT) sensor data that measures changes in equipment across a facility.
Common usecase in AWS cloud is to write and read the data from the sensors or devices to the Timestream with Lambda. Typically the Timestream DB in AWS offered endpoint which was accessible for lambda over the internet traffic what is very often not desired scenario. With the VPC endpoint for the Timestream DB the data are flowing through AWS internally provisioned VPN connection between you subnet and Timestream DB.
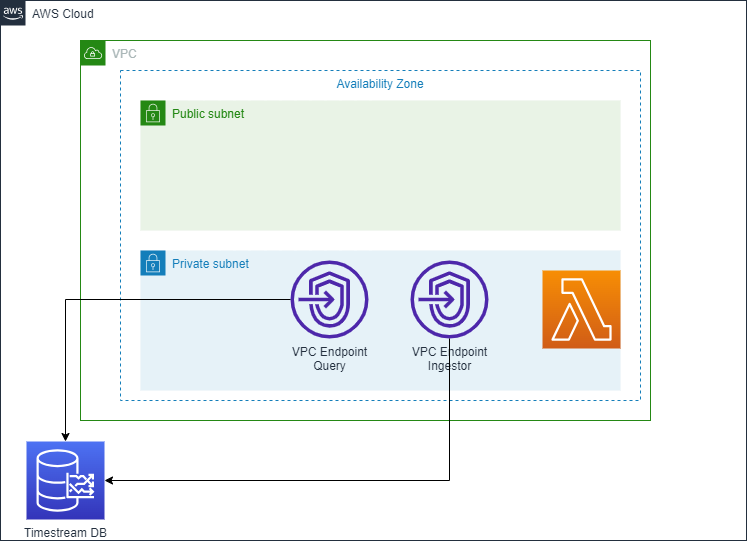
Assumptions :
- Created and provisioned Timestream DB
- VPC with at least 1 private subnet
- We use region eu-centra-1 (Frankfurt)
The format for the Timestream DB for write is : ingest-<cellx>.timestream.<region>.amazonaws.com or for api com.amazonaws.<region>.timestream.ingest-,cellx> and for query query-<cellx>.timestream.<region>.amazonaws.com or for api com.amazonaws.<region>.timestream.ingest-,cellx>.
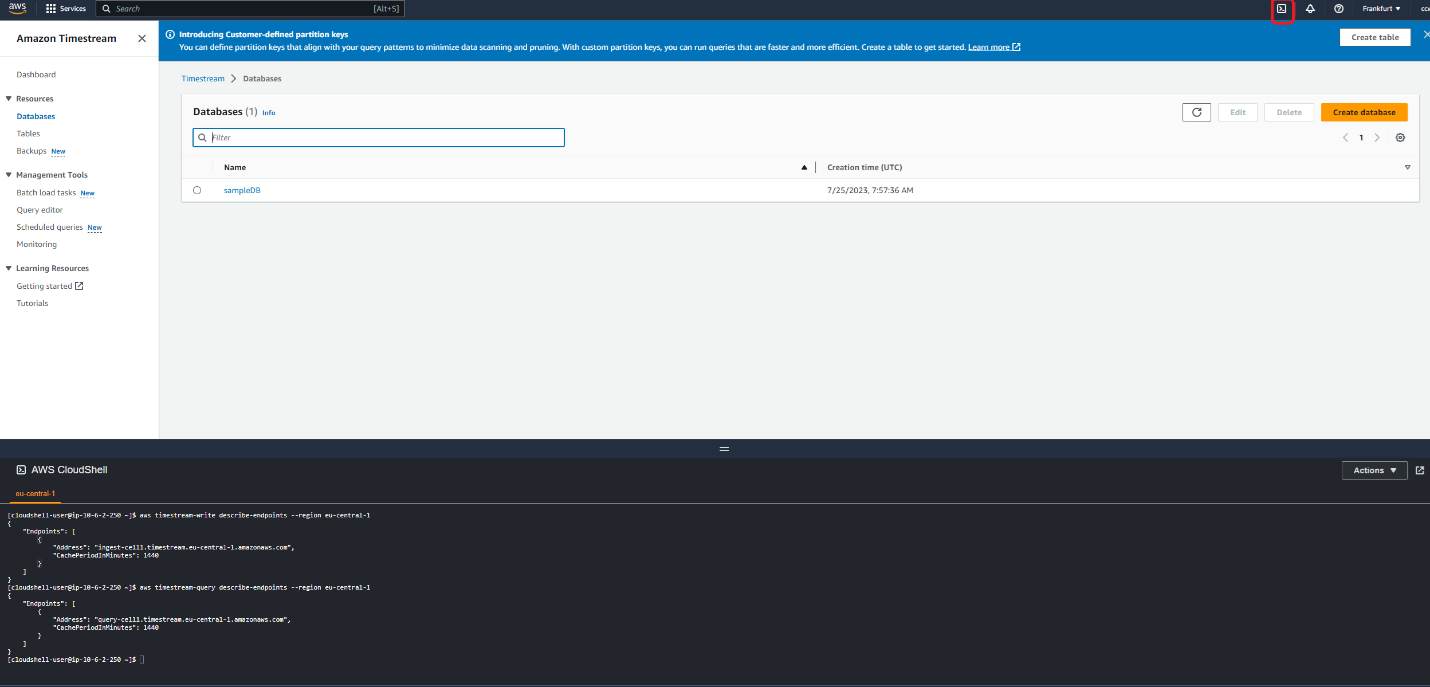
The variables region and cellx are as follows : for region we use eu-cental-1 what is Frankfurt. The <cellx> can be retrieved as follows :
- Open the AWS console.
- paste command aws timestream-query describe-endpoints --region eu-central-1
The result is :
{
"Endpoints": [
{
"Address": "query-cell1.timestream.eu-central-1.amazonaws.com",
"CachePeriodInMinutes": 1440
}
]
}
The endpoint is
Write : ingest-cell1.timestream.eu-central-1.amazonaws.com alebo com.amazonaws.eu-central-1.timestream.ingest-cell1
Query : query-cell1.timestream.eu-central-1.amazonaws.com alebo com.amazonaws.eu-central-1.timestream.query-cell1
Check the query for your Timestream DB :
aws timestream-query query --query-string "SELECT * FROM sampleDB.IoTMulti ORDER BY time DESC LIMIT 10" --region eu-central-1 --endpoint-url https://query-cell1.timestream.eu-central-1.amazonaws.com
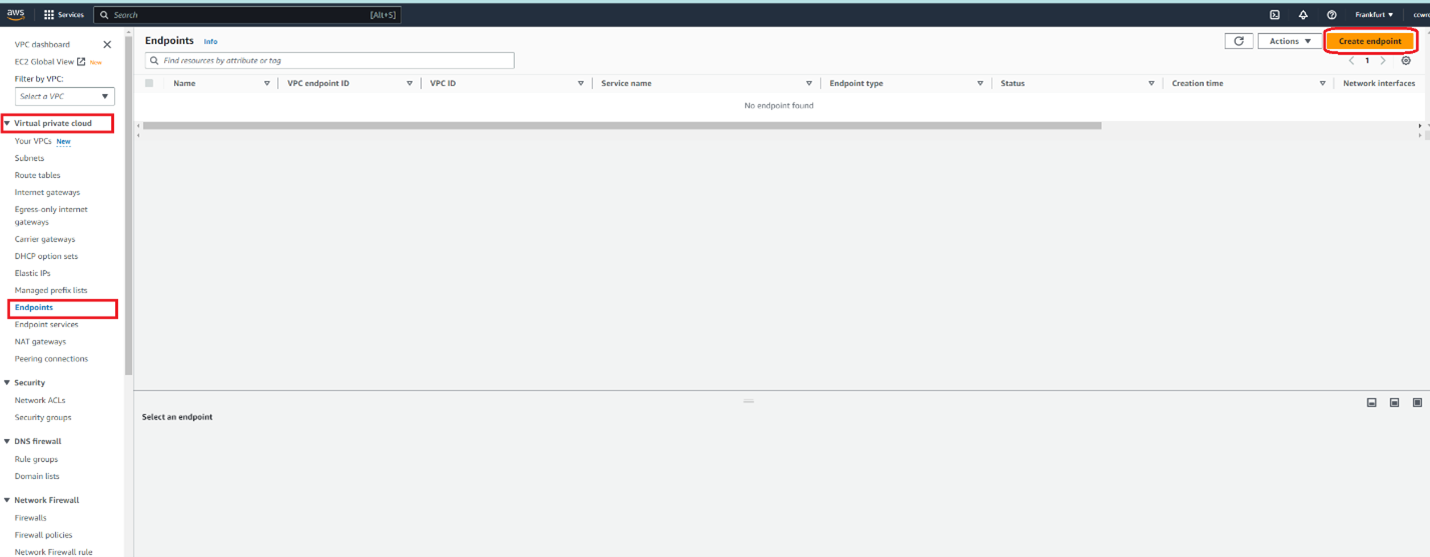
Now we are ready to configure the VPC endpoint for service AWS Timestream DB which will be used by lambda. The steps are :
1. Create VPC->Security groups for lambda : Outbound rules : Type : HTTPS, Protocol : TCP, Port range : 441, Source : X.X.X.X/XX based on your VPC.
2. Create VPC endpoint for ingest and query into Timestream DB. VPC->Endpoints>>Create endpoint.
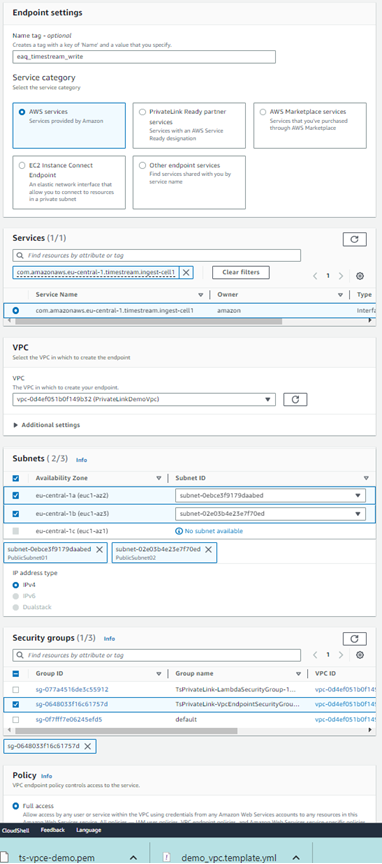
- Name : timestream_writte
- Service category : AWS services
- Services : search for com.amazonaws.eu-central-1.timestream.ingest-cell1
- VPC :your VPC
- Subnets : AZ a Subnet Id , kde je lambda a site-to-site vpn a odkial sa bude čítať a písať do timestream
- Security groups : vyber SG z bodu 2
- Policy : Full access
- Click <create endpoint>
- Name : timestream_query
- ervice category : AWS services
- Services : search for com.amazonaws.eu-central-1.timestream.query-cell1
- VPC :your VPC
- Subnets : AZ a Subnet Id , kde je lambda a site-to-site vpn a odkial sa bude čítať a písať do timestream
- Security groups : vyber SG z bodu 2
- Policy : Full access
- Click <create endpoint>
Now you can test your lambda to read from your timestream DB , we created sample lambda for python , added the VPC and private subnet to it. configured appropriate timestream db role:
import os
import json
import boto3
def lambda_handler(event, context):
json_region = os.environ['AWS_REGION']
DBName = 'sampleDB'
client = boto3.client('timestream-query')
SQL = "SELECT * FROM sampleDB.IoTMulti ORDER BY time DESC LIMIT 10"
paginator = client.get_paginator('query')
pageIterator = paginator.paginate(
QueryString=SQL)
results = []
count = 0
for page in pageIterator:
count += 1
if 'Rows' not in page or len(page['Rows']) == 0:
continue
else:
results.extend(page['Rows'])
print(count, len(results))
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"Region ": json_region,
"count ": len(results)
})
}
Conclusion
AWS cloud is the biggest cloud with over 200+ cloud services. We have demonstrated how to integrate IoT designed Timestream DB with lambda over VPC endpoint. CCW is a selected AWS partner and we have competences to guide you throughout your cloud AWS journey. Contact us.
Back to Blog